![IO.NET [ Formerly ANTBIT ]](https://files.readme.io/ae596fc-IO_DOCS_.svg)
Overview
Powered by Solana & Aptos
Our Mission: Build the world's largest AI compute DePIN (decentralized physical infrastructure network)

io.net is building an enterprise-grade decentralized computing network that allows machine learning engineers to access distributed cloud clusters at a small fraction of the cost of comparable centralized services.
We believe that compute is this generation's "digital oil," powering a never before seen technological industrial revolution. Our vision is to build IO to be the currency of compute, powering an ecosystem of products and services that enable access to compute as a resource and as an asset.
Modern machine learning models frequently leverage parallel and distributed computing. It is crucial to harness the power of multiple cores across several systems to optimize performance or scale to larger datasets and models. Training and inference processes are not just simple tasks running on a single device but often involve a coordinated network of GPUs that work in synergy.
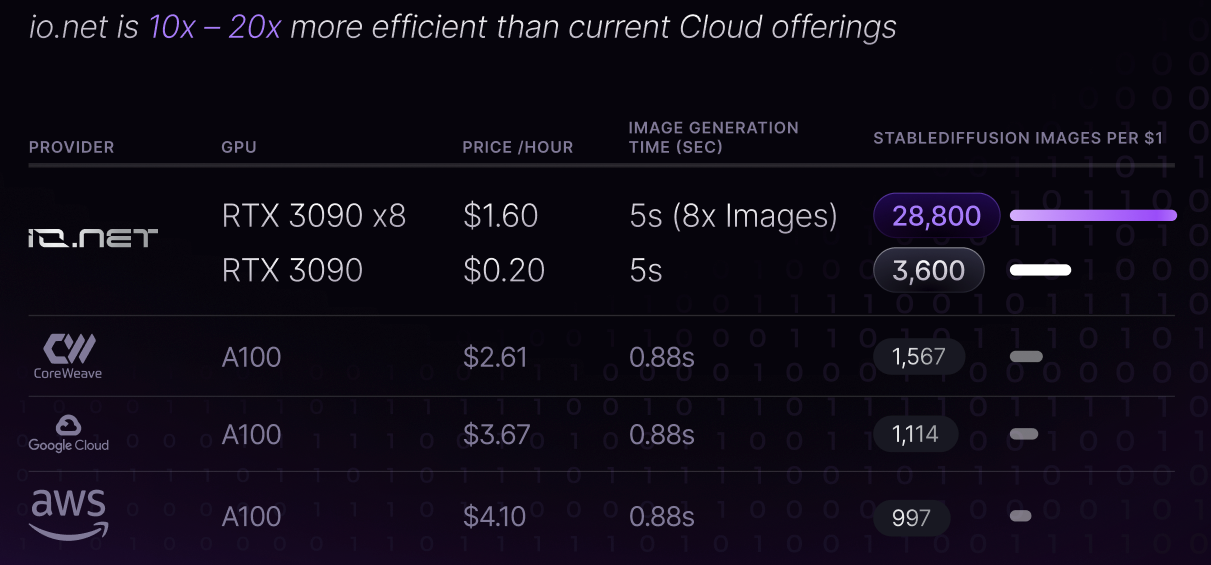
However traditional cloud service providers have 2.5x less capacity than the estimated demand in the market from AI/ML companies, making access to distributed computing resources presents several challenges. Some of the most prominent are:
- Limited Availability: It can often take weeks to get access to hardware using cloud services like AWS, GCP or Azure, and popular GPU models are often unavailable.
- Poor Choice: Users have little choice regarding GPU hardware, location, security level, latency and other options.
- High Costs: Getting good GPUs is extremely expensive, and projects can easily spend hundreds of thousands of dollars monthly on training and inferencing.
io.net solves this problem by aggregating GPUs from underutilized sources such as independent data centers, crypto miners, and other hardware networks like Filecoin, Render and others. These resources are combined within a Decentralized Physical Infrastructure Network (DePIN), giving engineers access to massive amounts of on-demand computing power in a system that is accessible, customizable, cost-efficient and easy to implement.
With io.net, teams can scale their workloads across a network of GPUs with minimal adjustments. The system handles orchestration, scheduling, fault tolerance, and scaling and supports a variety of tasks such as preprocessing, distributed training, hyperparameter tuning, reinforcement learning, and model serving. It is designed to serve general-purpose computation for Python workloads, with an emphasis on serving AI/ML workloads.
io.net offering is purpose-built for four core functions:
- Batch Inference and Model Serving: Performing inference on incoming batches of data can be parallelized by exporting the architecture and weights of a trained model to the shared object-store. io.net allows machine learning teams to build out inference and model-serving workflows across a distributed network of GPUs.
- Parallel Training: CPU/GPU memory limitations and sequential processing workflows present a massive bottleneck when training models on a single device. io.net leverages distributed computing libraries to orchestrate and batch-train jobs such that they can be parallelized across many distributed devices using data and model parallelism.
- Parallel hyperparameter tuning: Hyperparameter tuning experiments are inherently parallel, and io.net leverages distributed computing libraries with advanced Hyperparam tuning for checkpointing the best result, optimizing scheduling, and specifying search patterns simply.
- Reinforcement learning: io.net uses an open-source reinforcement learning library, which supports production-level, highly distributed RL workloads alongside a simple set of APIs.
It all started at the Solana Hackathon, Feb 2023 and the Solana Austin Hacker House

Updated about 1 month ago